原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 4年前 (2020-06-18) 1832℃ 0评论4喜欢
经过几天的折腾,终于配置好了Hadoop2.2.0(如何配置在Linux平台部署Hadoop请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》),今天主要来说说怎么在Hadoop2.2.0伪分布式上面运行我们写好的Mapreduce程序。先给出这个程序所依赖的Maven包:[code lang="JAVA"]<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> w397090770 11年前 (2013-10-29) 20357℃ 6评论10喜欢
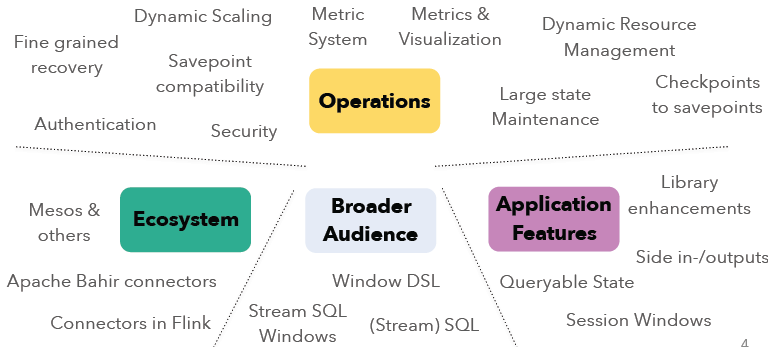
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方向:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 w397090770 8年前 (2016-12-18) 2821℃ 0评论4喜欢
在《Spark读取Hbase中的数据》文章中我介绍了如何在Spark中读取Hbase中的数据,并提供了Java和Scala两个版本的实现,本文将接着上文介绍如何通过Spark将计算好的数据存储到Hbase中。 Spark中内置提供了两个方法可以将数据写入到Hbase:(1)、saveAsHadoopDataset;(2)、saveAsNewAPIHadoopDataset,它们的官方介绍分别如下: saveAsHad w397090770 8年前 (2016-11-29) 17881℃ 1评论29喜欢
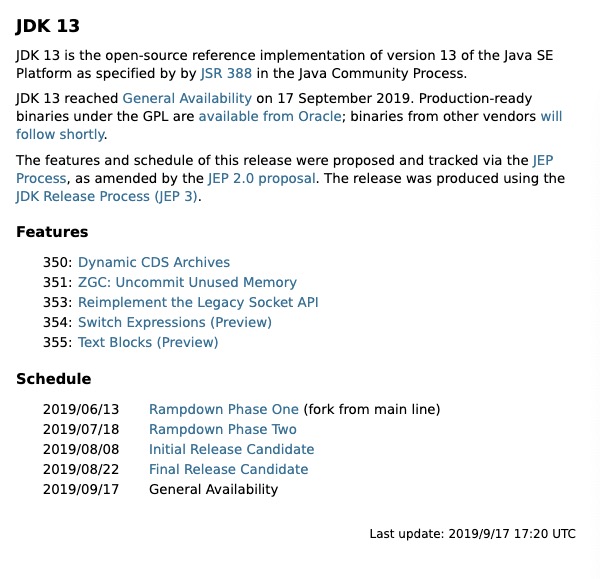
就在昨天(2019年09月17日),JDK 13 已经处于 General Availability 状态,已经正式可用了。General Availability(简称 GA)是一种正式版本的命名,也就是官方开始推荐广泛使用了,我们熟悉的 MySQL 就用 GA 来命令其正式版本。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从上图我们可以看到 JDK 13 带来了 w397090770 5年前 (2019-09-18) 1547℃ 0评论1喜欢
Zomato 是一家食品订购、外卖及餐馆发现平台,被称为印度版的“大众点评”。目前,该公司的业务覆盖全球24个国家(主要是印度,东南亚和中东市场)。本文将介绍该公司的 Food Feed 业务是如何从 Redis 迁移到 Cassandra 的。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoopFood Feed 是 Zomato 社交场景 w397090770 5年前 (2019-09-08) 1128℃ 0评论2喜欢
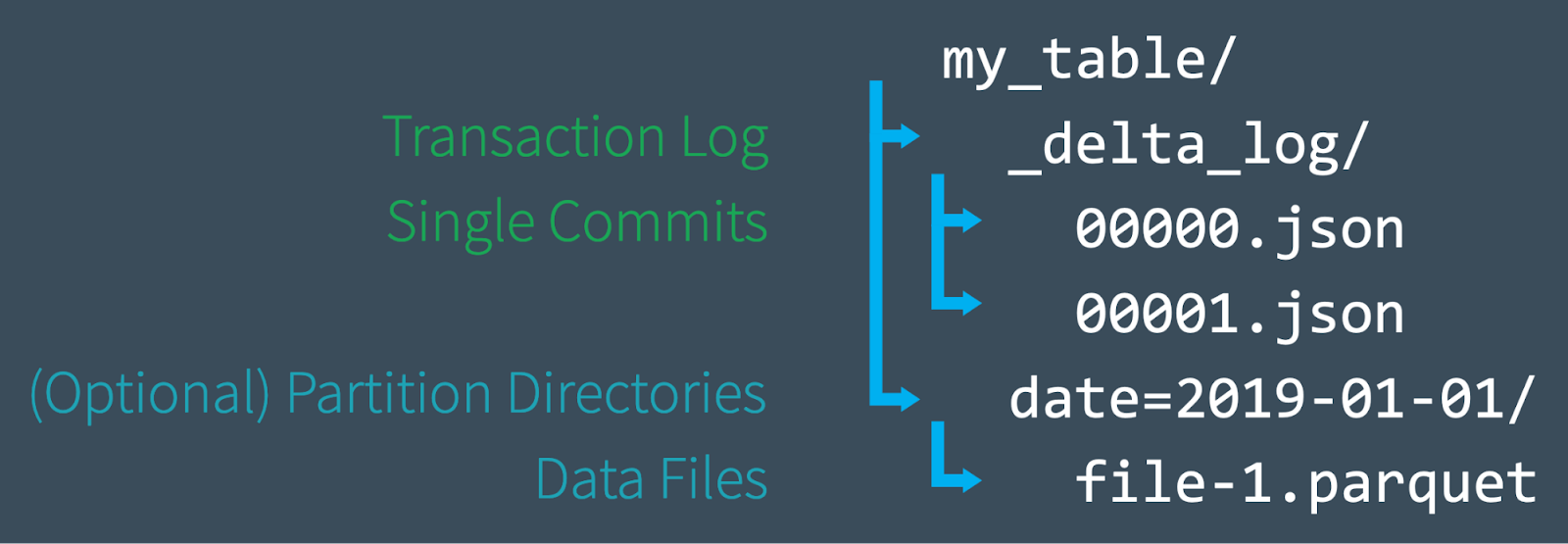
Delta Lake 支持 DML 命令,包括 DELETE, UPDATE, 以及 MERGE,这些命令简化了 CDC、审计、治理以及 GDPR/CCPA 工作流等业务场景。在这篇文章中,我们将演示如何使用这些 DML 命令,并会介绍这些命令的后背实现,同时也会介绍对应命令的一些性能调优技巧。Delta Lake: 基本原理如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 4年前 (2020-10-12) 1438℃ 0评论0喜欢
本书将为您简要介绍ElasticSearch的基础知识以及Elasticsearch 5的新功能。通过本书将学习到Elasticsearch的基本功能和高级功能,例如查询,索引,搜索和修改数据。本书还介绍了一些高级知识,包括聚合,索引控制,分片,复制和聚类。中间部分介绍了ElasticSearch集群相关的知识,包括备份、监控、恢复等。读完本书,您将掌握Elastics zz~~ 8年前 (2017-02-28) 4963℃ 0评论13喜欢
Hive可以运行保存在文件里面的一条或多条的语句,只要用-f参数,一般情况下,保存这些Hive查询语句的文件通常用.q或者.hql后缀名,但是这不是必须的,你也可以保存你想要的后缀名。假设test文件里面有一下的Hive查询语句:[code lang="JAVA"]select * from p limit 10;select count(*) from p;[/code]那么我们可以用下面的命令来查询:[cod w397090770 11年前 (2013-11-06) 10143℃ 2评论5喜欢
我们在使用Spark的时候有时候需要将一些数据分发到计算节点中。一种方法是将这些文件上传到HDFS上,然后计算节点从HDFS上获取这些数据。当然我们也可以使用addFile函数来分发这些文件。addFile addFile方法可以接收本地文件(或者HDFS上的文件),甚至是文件夹(如果是文件夹,必须是HDFS路径),然后Spark的Driver和Exector w397090770 8年前 (2016-07-11) 12593℃ 0评论13喜欢
本文来自本人于2018年12月25日在 HBase生态+Spark社区钉钉大群直播,本群每周二下午18点-19点之间进行 HBase+Spark技术分享。加群地址:https://dwz.cn/Fvqv066s。本文 PPT 下载:关注 iteblog_hadoop 微信公众号,并回复 HBase_Rowkey 关键字获取。为什么Rowkey这么重要RowKey 到底是什么如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 w397090770 6年前 (2018-12-25) 7431℃ 0评论29喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas w397090770 8年前 (2016-11-28) 17774℃ 2评论52喜欢
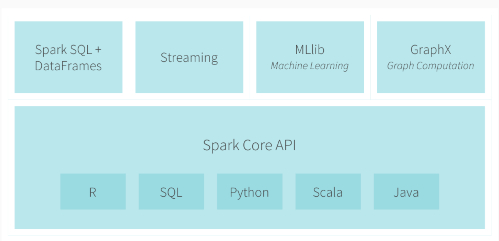
现在Apache Spark已形成一个丰富的生态系统,包括官方的和第三方开发的组件或工具。后面主要给出5个使用广泛的第三方项目。Spark官方构建了一个非常紧凑的生态系统组件,提供各种处理能力。 下面是Spark官方给出的生态系统组件 1、Spark DataFrames:列式存储的分布式数据组织,类似于关系型数据表。 2、Spark SQL:可 w397090770 9年前 (2016-03-08) 4939℃ 2评论7喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 9年前 (2016-02-02) 20643℃ 9评论20喜欢
Apache Pulsar(孵化器项目)是一个企业级的发布订阅(pub-sub)消息系统,最初由Yahoo开发,并于2016年底开源,现在是Apache软件基金会的一个孵化器项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo Mail、Yahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa。如果想及时了解Spark、Hadoop w397090770 7年前 (2018-01-16) 1991℃ 0评论9喜欢
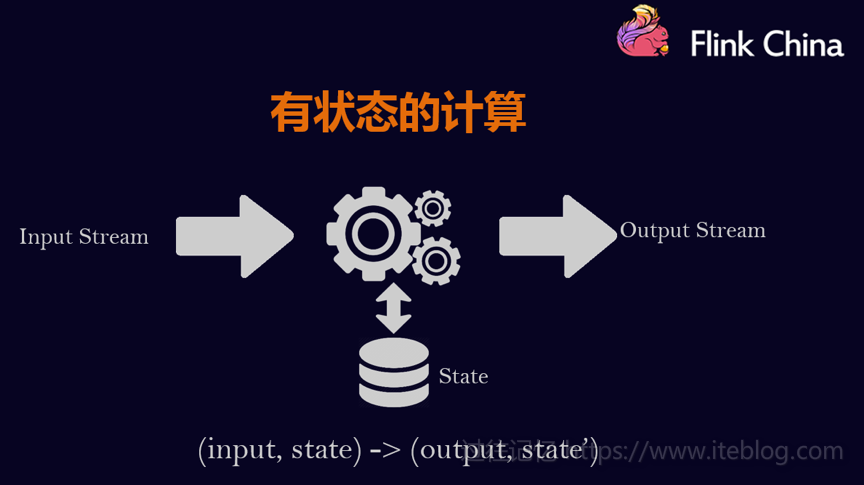
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 6年前 (2018-08-24) 9091℃ 0评论21喜欢
Spark 1.1.0马上就要发布了(估计就是明天),其中更新了很多功能。其中对Spark SQL进行了增强: 1、Spark 1.0是第一个预览版本( 1.0 was the first “preview” release); 2、Spark 1.1 将支持Shark更新(1.1 provides upgrade path for Shark), (1)、Replaced Shark in our benchmarks with 2-3X perfgains; (2)、Can perform optimizations with 10- w397090770 10年前 (2014-09-11) 7778℃ 2评论5喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop回望过去10年,数据技术发展迅速,数据也在呈现爆炸式的增长,这也伴随着如下两个现象。一、数据更加分散:企业的数据是散落在不同的数据存储之中,如对象存储OSS,OLTP的MySQL,NoSQL的Mongo及HBase,以及数据仓库ADB之中,甚至是以服务的形式 w397090770 5年前 (2020-01-07) 1187℃ 0评论3喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ 这些天看到很多人在使用H w397090770 11年前 (2013-12-25) 25275℃ 0评论23喜欢
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的问题; 2、At least once - 每条数据最少被处理一次 (1 w397090770 8年前 (2016-07-26) 10905℃ 3评论17喜欢
Alluxio Meetup 上海站由 Alluxio、七牛主办,示说网、过往记忆协办,本次会议将于2018年10月27日 13:30-17:00 在上海市张江高科博霞路66号浦东软件园Q座举行。报名地址扫描下面二维码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动详情Alluxio:未来是数据的时代,数据的高效管理、存储 w397090770 6年前 (2018-10-17) 1308℃ 0评论1喜欢
Short URL or tiny URL is an URL used to represent a long URL. For example, http://tinyurl.com/45lk7x will be redirect to http://www.snippetit.com/2008/10/implement-your-own-short-url.There are 2 main advantages of using short URL: Easy to remember - Instead of remember an URL with 50 or more characters, you only need to remember a few (5 or more depending on application's implementation). More portable - Some systems have limi w397090770 12年前 (2013-04-15) 20484℃ 0喜欢
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开: 1、Flink-connector稳定性优化 2、Flink sql优化 3、Flink-runtime优化 4、对未来的展望 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 概述首先介绍下Flink实时计算在b站的应用场景。在b站,Flink on yarn w397090770 3年前 (2021-09-23) 851℃ 0评论4喜欢
第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 7年前 (2017-12-06) 2020℃ 0评论11喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存 w397090770 9年前 (2016-02-05) 10254℃ 1评论12喜欢
本博客收集的手机号段截止时间为2020年03月的,共计450000+条。包含以下字段:电信:133 153 173(新) 177 (新) 180 181 189 199 (新)移动:134 135 136 137 138 139 150 151 152 157 158 159 172(新) 178(新) 182 183 184 187 188 198(新) 联通:130 131 132 155 156 166(新) 175(新) 176(新) 185 186数据卡:145 147 149其他:170(新) 171 (新)API地址/api/mobile.php使用本AP w397090770 8年前 (2016-08-02) 5075℃ 0评论15喜欢
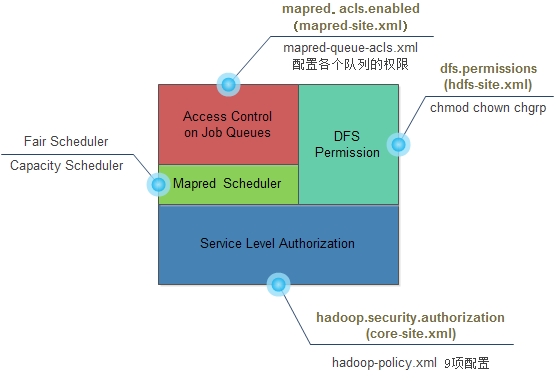
Hadoop在服务层进行了授权(Service Level Authorization)控制,这是一种机制可以保证客户和Hadoop特定的服务进行链接,比如说我们可以控制哪个用户/哪些组可以提交Mapreduce任务。所有的这些配置可以在$HADOOP_CONF_DIR/hadoop-policy.xml中进行配置。它是最基础的访问控制,优先于文件权限和mapred队列权限验证。可以看看下图[caption id="attach w397090770 11年前 (2014-03-20) 9091℃ 0评论8喜欢
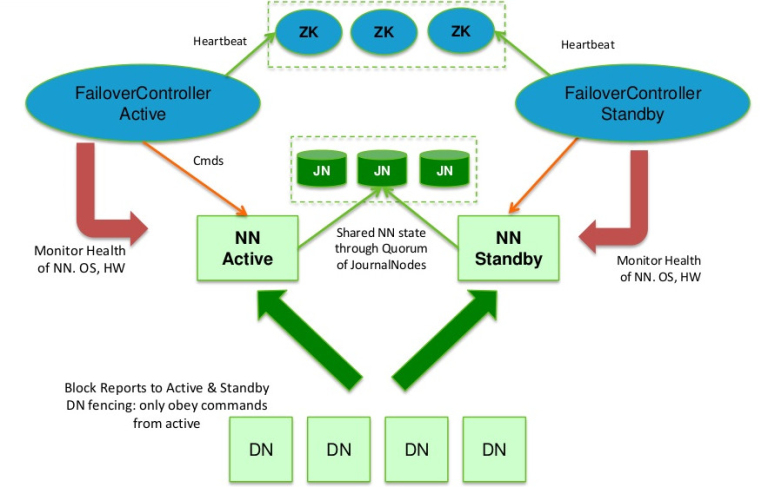
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 11年前 (2013-11-14) 10632℃ 3评论22喜欢
FFmpeg 是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,采用 LGPL 或 GPL 许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库 libavcodec,为了保证高可移植性和编解码质量,libavcodec 里很多 code 都是从头开发的。如果想及时了解Spark、Hadoop或者HBase相 w397090770 3年前 (2021-04-30) 796℃ 0评论2喜欢
本书书名全名:Learning Spark Streaming:Best Practices for Scaling and Optimizing Apache Spark,于2017-06由 O'Reilly Media出版,作者 Francois Garillot, Gerard Maas,全书300页。本文提供的是本书的预览版。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand how Spark Streaming fits in the big pictureLearn c zz~~ 7年前 (2017-10-18) 6450℃ 0评论21喜欢



![[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载](https://www.iteblog.com/pic/elastic/Mastering_Elasticsearch_5.x-Third_Edition_iteblog.jpg)



![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)






![[电子书]Learning Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Spark_Streaming_iteblog.jpg)